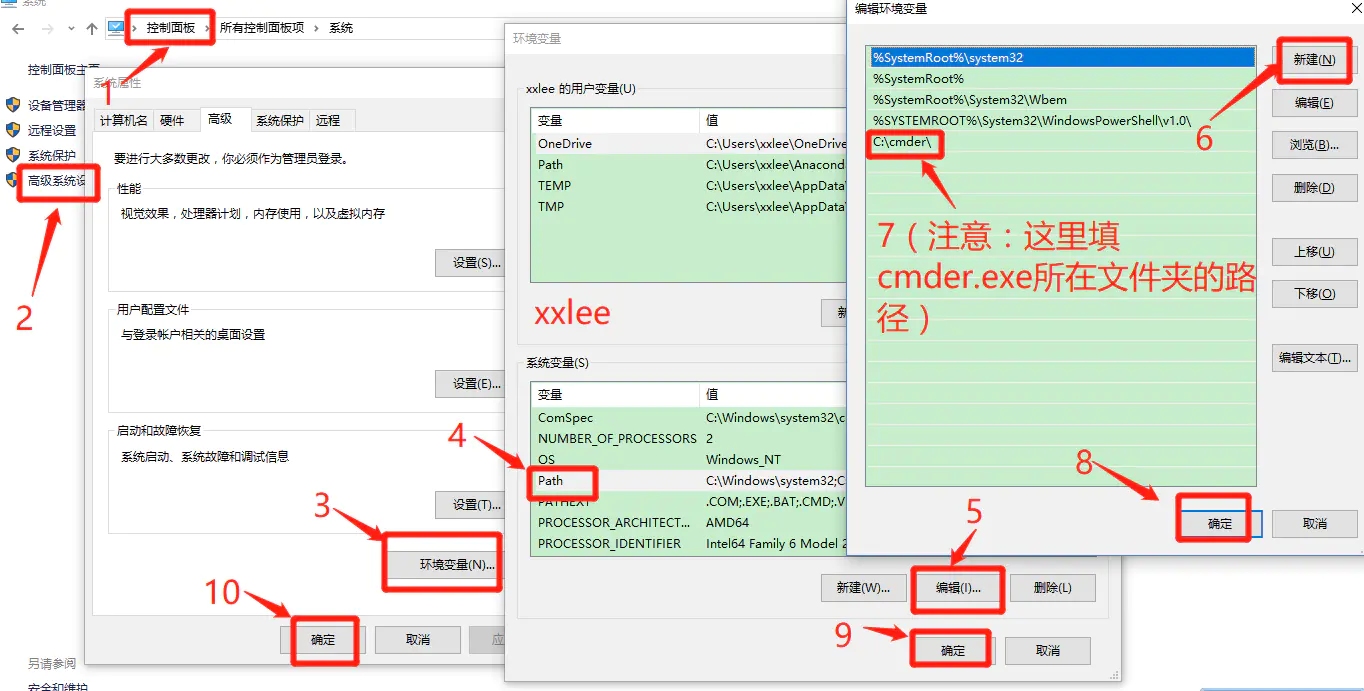
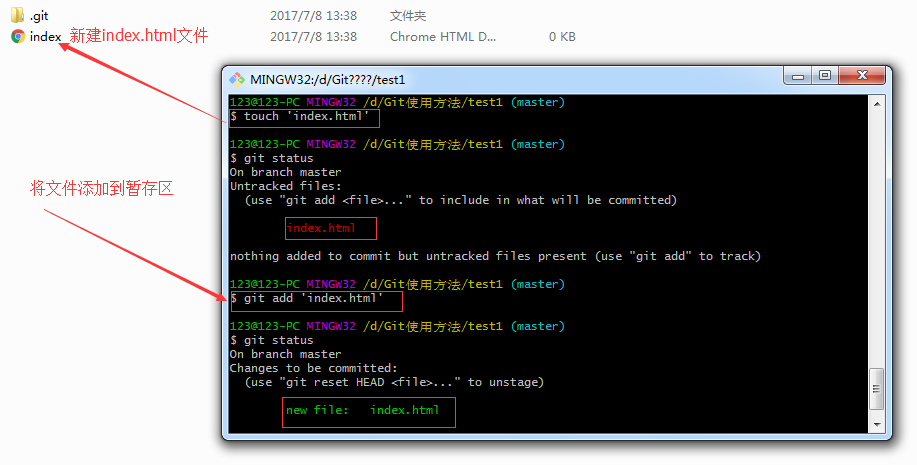
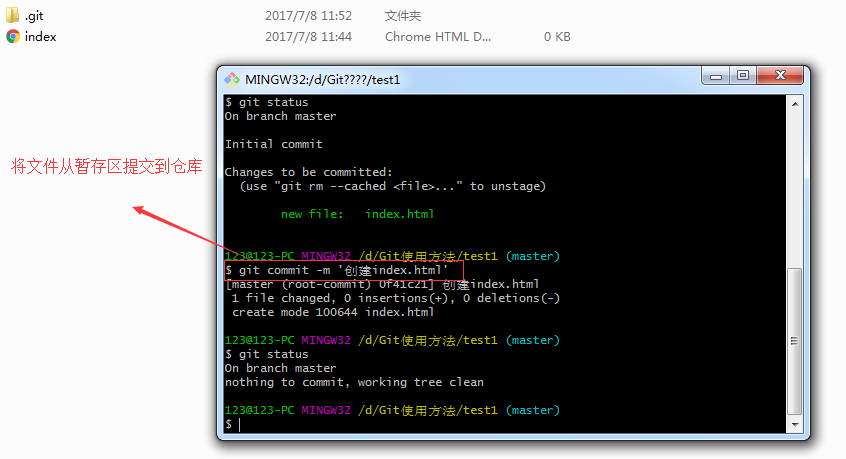
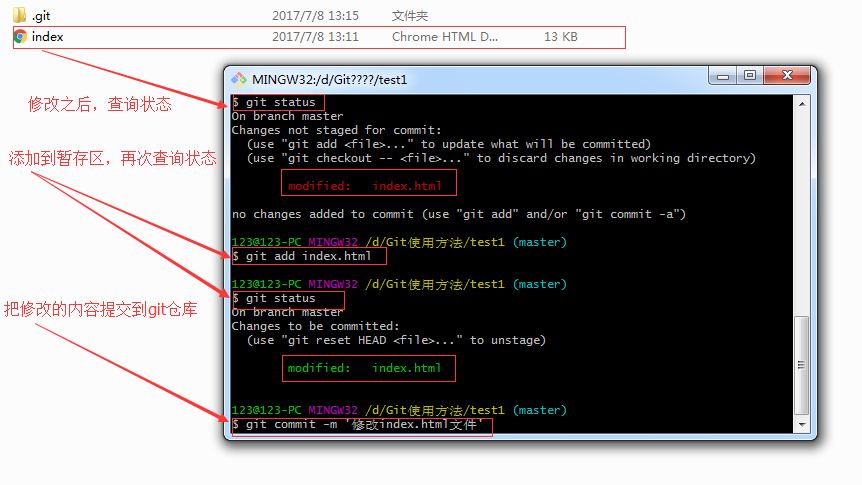
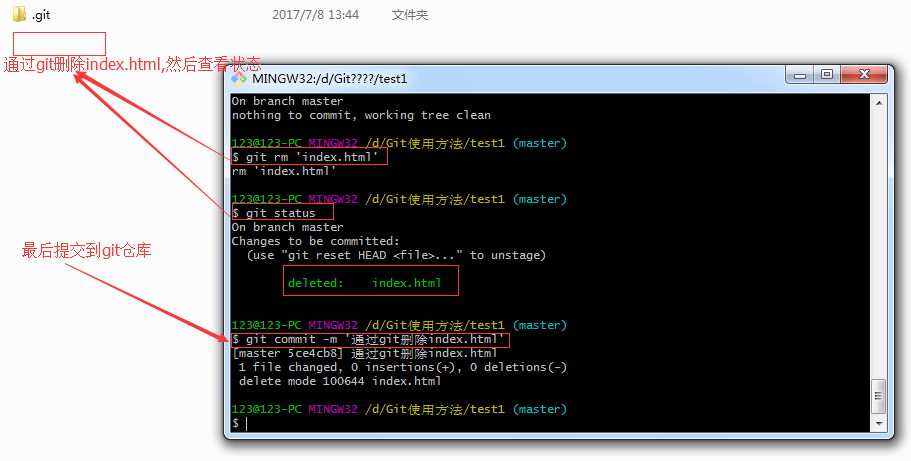
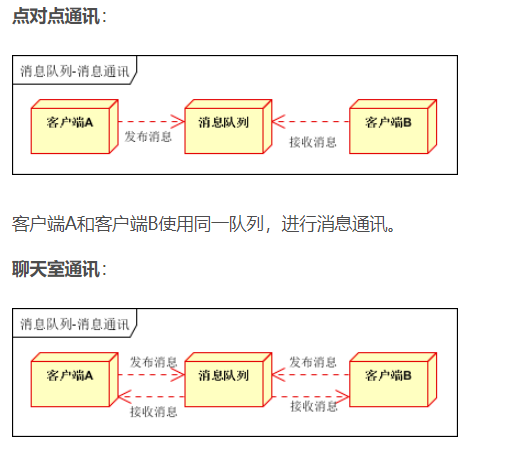
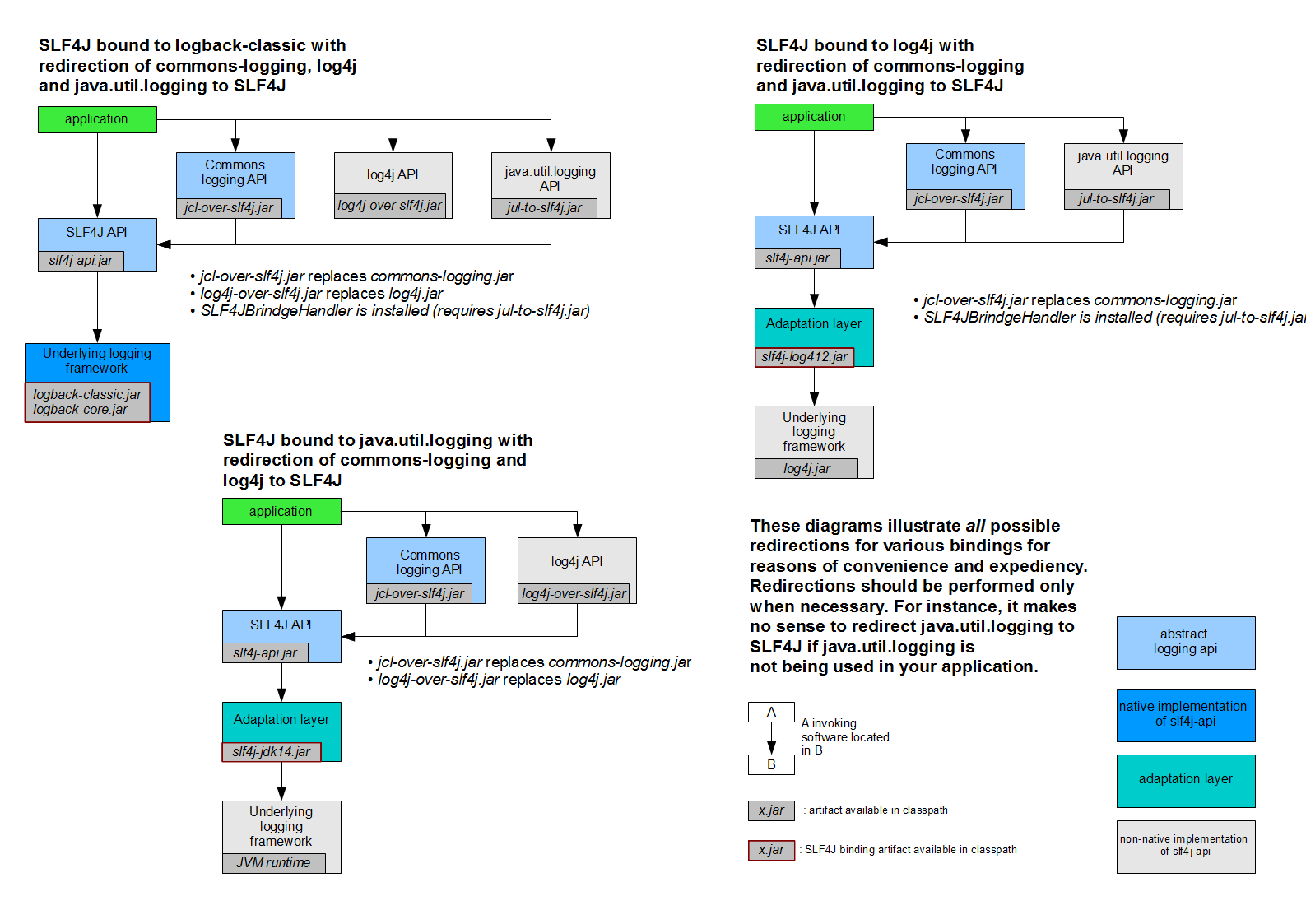
介绍
《原则》全书一共分为三个部分 : 第一部分是个人经历的介绍;第二部分是生活原则的描述;第三部分是工作原则的描述。
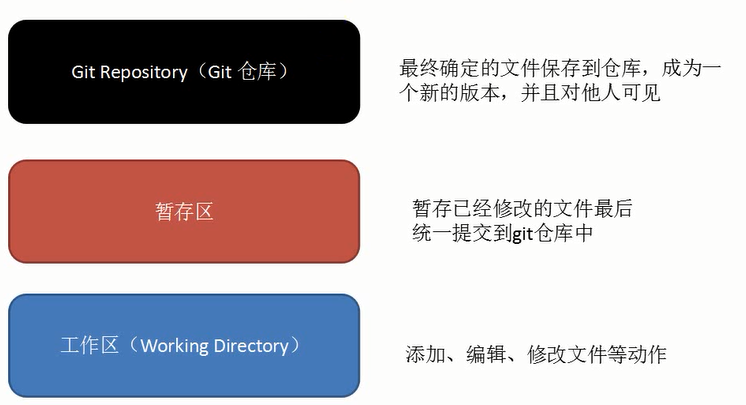
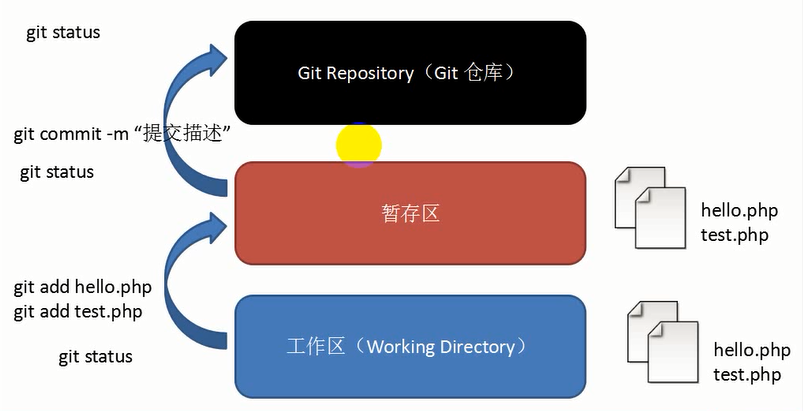
生活原则
拥抱现实;应对现实
- 不要混淆愿望与现实
- 不要担心自己形象;而关心能不能实现你的目标
- 要重视后续的结果以及后续的后续
- 不要让痛苦妨碍自己的进步
- 不要把不好归咎与任何人;从自己身上找原因
做一个超级现实的人
在乎梦想;但是扎根于现实
梦想 + 现实 + 决心 = 成功的生活
理解现实;是任何良好结果的根本依据
因为当真相与愿望不符的时候;大部分人抗拒真相。 这种认知偏差;有很多心理学现象与之相关;如房间里的大象等。在《需求》 和 《思考快与慢中》都有过相关的论述。说到底;就是要扎根现实。理解现实,然后,改变自己;改变现实
头脑需要极度开放
头脑极度开放;极度透明有利于快速学习与改进
这几乎是整个生活原则中最重要的一条原则了
你头脑越是开放,越是不会自欺欺人。其他人给你的反馈就会更加诚实(“你如果是喜欢听与自己意见一样的话;就会得到的反馈就越是虚假”)
如果这些人是可信的人 ;你将会收获很多。
不要担心其他人的看法;那会成为你的障碍
你必须以你认为最好的独特的方式行事;这样做一定会收到反馈;我们必须以开放的头脑思考这些反馈。
尽管你的极度透明会让你感觉到不舒服;但是这样对你是最好的。
极度求真,极度透明会带来更加有意义的工作和更好的人际关系
观察自然;学习现实规律
两种视角:
自上而下 找事务背后规律: 理解市场;供求关系;宏观大势
自下而上去验证具体情况 : 验证具体情况是否相符合
不要固守你认为事物 “应该” 是什么样子
保持客观: 不要让偏见使我们无法认识客观情况。
当看到一个认为自然是错误的想法的时候,先假设自己是错的,然后想办法弄明白为什么自然如此是合理的。
一个例子: 大草原上鬣狗吃了小幼马,我们会心生同情。但是事实上这是自然法则,自然会走向整体最优,而不是个体最优化。
人也是一样。人们会把对自己或者自己相关的人不利的事情叫做坏事,而忽略更大的好。 群体中也有这种倾向,如宗教歧视。
只根据事务对个人的影响就判断绝对的好与坏是不合理的。(这点很难做到)
一个东西要好,必须符合现实规律,并促进整体的进化。这会带来更大的好。
进化是宇宙中最强大的力量
这里推荐一本书:《基因之河》;
关于进化:还有一本书,《自私的基因》, 也非常开脑洞。
进化是生命最大的成就和回报
个人激励机制必须符合群体目标。
比如自然给了性行为个体巨大的快乐激励,来达到群体的不断进化迭代。
现实为了趋向整体最大化,而不是个体。
为了整体做贡献,你就有可能收到回报。自然选择让更好产品得以保留,结果是整体的最优化。
通过快速试错以适应现实是无价的。
实验和适应能带来更快的进步。
要意识到你即是一切,又什么都不是,并决定你想成为什么样子。
“个人即是一切,又什么都不是,这是一个巨大的悖论。”
你的未来取决于你的视角。
你的未来取决于你的如何看待事物,关心什么事物。
必须决定你多大程度将别人的利益放在你的自己利益之上。
拥抱现实,从自然的角度俯视自身很美妙。
理解自然提供的现实教训
收益递减规律。
任何东西在从太少变太多的过程中,边际收益都会递减。
没有痛苦就没有收获。
“人需要困难,这对健康来说是必须的。”
痛苦 + 反思 = 进步
如果以正确的态度面对痛苦,感到痛苦就是你的幸运!!即使反思痛苦。
最好的就是在痛苦的当时就进行反思。
考虑后续与再后续的结果
直接结果很可能是诱惑或者痛苦。
如果因为直接结果的痛苦而不去做,就很难获得大的成功。
如果因为直接结果的诱惑而去做了,就会遭遇更大的失败。
接受结果:内控点
在生活中不论遇到什么情况,如果你能够负起责任,进行良好的决策,而不是抱怨你无法控制的事情,你将更加容易知找到幸福。
不要为喜不喜欢自己的处境担忧,你必须根据自己的愿望找到实现愿望的途径。然后,鼓起勇气坚持下去。
后面的五步流程会给到你一定帮助。
从更高的层次腐蚀机器
想象自己是一个大机器里的一个小机器,拥有改变自己而变得更好的能力。
通过比较你实现的结果和你的目标,你就能确定如何改进你的机器。
却别作为机器设计者的你和作为机器中工作者的你。
最难的事情是在自身所处的环境中,客观的看待我们自己,不高看自己,不承担不应该承担的任务。
擅于请教领域达人,因为你很难客观看待自己,所以你需要依赖他人的意见以及证据。
如果你头脑开放,足够有决心,你几乎可以实现任何愿望。
五部流程,实现你的人生愿望
- 明确目标
- 找到阻碍目标的问题,并且不容忍问题
- 准确诊断问题,找到问题根源
- 规划可以解决问题的方案
- 做一切必要的事儿来践行这些方案,实现成果
这五个步骤形成一个循环。
需要注意的点是:
专注每个点。设定目标的时候就设定目标,不要想实现和出错(延迟批判)。
当你诊断问题的时候,就不要想如何解决问题,混淆这两个问题会导致你无法发现真正的问题。
坚持这些规则。挫折,会让你难受,不完美永远存在。好消息是你可以从错误中吸收学习和成长。
坚持下去你就会有收获。
有明确的目标
排列目标优先级。你几乎可以得到你想要的任何东西,但你无法得到所有东西。
分清目标和欲望
目标是你真正需要的东西
欲望是你想要但会阻碍你实现目标的东西(比如偷懒)
不要因为某个目标无法实现就否定它
伟大的期望创造伟大的能力
拥有灵活性和自我归咎,那没什么能阻止你
知道如何应对挫折很重要
逆境中,重要的是守住优势,减少损失
你的任务永远是做出尽可能少的选择
成功不难,关键在于少犯错误
找出问题但是不容忍
令人痛苦的问题当做考验你潜在进步的机会
当你遇到一个问题,那就是一个机会。 大多数人不喜欢这么做
不要逃避问题,承认问题是改变的第一步
忍痛前行,痛苦会给你汇报
不要把某个原因当做问题本身
我无法得到很好的睡眠是一个原因,我工作效率低是一个问题,前者可能是后者的原因。
重点解决大问题
找到问题根源
弄清楚问题,这需要时间去诊断,一次良好的诊断一般需要15-60分钟。
区分直接与根本原因
规划方案
前进之前先回顾
设置方案,写下来所有人都能看到,严格执行
规划先于行动,好规划不一定要很多时间
坚定的从头到尾执行方案
保持谦逊
与其他人高质量交流
保持谦逊,你可以从别人那里得到你需要的东西
找到你最大的弱点,并处理掉
理解自己的认知,理解他人与你不同
提升认知能力,保持头脑开放,从他人那里获得帮助,你可以实现很多事情
做到头脑极度开放
这一章几乎是生活原则中最重要的一章。(雷达里奥说;这也是全书最重要的一章)
主要重点有两个: 一个是为什么要保持头脑开放;一个是什么情况下你是头脑封闭的。
认识到第二点其实很重要,这会帮助你的日常反思。
认识到自己的障碍和不足;
寻求可信度高的人的意见,设身处地思考和理解,对比自己的,最终做出更好的决策。
认识你的两大障碍
障碍一:意识障碍;理解你的自我意识障碍
主要是你潜意识里的防备机制; 使你难以接受你的错误和缺点。
我们有一些根植于内心的需求:
- 被爱
- 被需要
- 害怕死亡
- 害怕失去
- 害怕自己无意义
不能让“想要自己正确的需求 ” 压倒 “找出真相” 的需求
当有人和你意见不一样;并且要求你解释的时候;你的大脑会把这样的东西当做 攻击;你会变得愤怒。
如果你想要成功;你需要克制这一点。 这样的人你也可以观察一下;身边到处都是。你也可以反思一下;你自己是不是这样的人。(怎么判断自己有这种倾向在后面会说到)
障碍二;思维障碍;理解你的思维盲点障碍
人很难理解自己看不到的东西;《需求》 这本书里也有说到 塞缪尔思反射 。
如果你一心只想告诉对方自己的认为正确的想法;你就是 一个头脑封闭的人
这样的话;当其他人给你展示各种可能性威胁和批评的时候;你可能会看不见。也无法领会。
奉行头脑极度开放;不仅仅是“承认自己可能错了”
如果你知道自己有盲点;你就能找到一种解决办法。
头脑开放不仅仅是“承认自己可能错了”,但是依旧坚持自己的观点。这样作用不大。
a. 诚恳的想想自己也许并不知道最好的解决办法是什么。能不能妥善处理“不知道”很重要
很多糟糕的决定是因为他们相信自己是对的。而头脑极度开放的人知道。找到问题的答案很重要。
b. 决策有两个步骤: 1 分析所有相关信息;2 决策
听听其他人的观点并加以思考,不会削弱你独立思考,自主决策的自由。只会帮你拥有更广的角度
c. 不要担心你的形象,只担心如何实现目标
做出优秀决策的人,很少坚信自己已经掌握了最好的答案,承认自己有缺点 和 盲点 ,并试图了解更多,克服缺陷和盲点。
d 不吸收,产出也不大好。
e 从他人的角度,设身处地,才能评估另一种观点的价值
高度接受自己错了的可能性,鼓励别人告诉自己错在哪里
f 记住:你是在寻找最好的答案,不是自己能得出最好的答案
知道自己不知道,无比重要。 自问一下,我是不是只是从自己的角度看问题
g 搞清楚你是在争论还是在试图理解一个问题,根据可信度,想想哪种更加合理
可信度 有两个特征:
反复的在相关领域成功找到答案(至少三次,拥有硬履历)
再被责问的情况下能对自己的观点做出很好的解释
领会并感激:深思熟虑的意见分歧
沟通方式要让对方觉得,你是试图在理解
你需要提问,而不是做出陈述,心平气和的进行讨论,并鼓励对方也这么做。
(某些时候)人们在产生分歧时变得愤怒是毫无意义的
当讨论陷入僵局,最没效果的就是,你试图在脑子中将所有的事情都弄得清楚。
和可信的,愿意表达分歧的人一起审视你的观点
既单独询问专家,也鼓励专家在我面前展现意见分歧。
为最坏的做准备。使其看起来不那么糟糕。
(重要)识别你头脑封闭的迹象
a 封闭的人:不喜欢看到自己的观点被挑战
不开放:会因为无法说服他人而沮丧,而不是好奇对方为何看法不同。
开放: 更想了解为什么会有分歧,明白自己可能是错的
b 封闭的人:喜欢做陈述而不是提问
开放的人,可信度很高的人,经常会提出很多问题。并真诚的相信自己可能是错的
c 封闭的人: 更关心自己是否被理解,而不是理解他人
封闭的人: 通常担心自己没有被理解
开放的人:觉得有必要从他人的视角看问题。
d 封闭的人:“我可能错了。。。但这是我的观点”
这是一个敷衍的回答,人们借此来固守自己的观点
最好提出一个问题,而不是做出一个断言
e 封闭的人 : 封闭的人,阻挠别人的发言
开放的人更喜欢倾听发言,鼓励表达
f 封闭的人 : 很难同时拥有两种想法
同时持有两种想法,并且能保持独立思考。
g 封闭的人 : 缺乏谦逊
开放的人: 时刻担忧自己可能是错误的。
如何做到头脑开放?
- 利用自己的痛苦进行高质量的思考
- 一旦觉得愤怒,冷静下来,以深思熟虑的方式看待眼前问题
- 一定要客观,愿意倾听
- 重视证据
- 冥想
理解人与人大大不相同
要理解:左脑思考偏逻辑,右脑思考偏情感。
要理解:最长发生的斗争就是意识与潜意识,情绪和思考的斗争。
如果你意识不到你的潜意识的存在,你的行为就会像西奥迪尼在《影响力》中做的那个比喻一样:是一个带着按钮的录音机;一按就播放。
比如:听到别人反对时候的被侵犯感。
要知道:我们可以改变,通过习惯。
如何做出正确的决策
好决策最大的敌人是坏情绪
如果你被情绪绑架,你将不可能作出好的决策。作出决策时候必须用逻辑,理性,事实。
正如荣格所说:“如果你不知道潜意识的存在,否则潜意识就会主导你的人生,而你称之为命运”
先了解,后决策
- 是什么 :先了解决策的基础知识,既包括“是什么”,也包括宏观的因果关系
“习惯性的问自己,我在了解相关情况吗?我已经掌握了决策的所有知识了么?”
为了了解:
要知道应该问什么人
不要高估自己的可信度
不要不区分别人的可信度(在相同领域有过3次以上成功经验的硬简历)
区分事实和观点,不要听到什么信什么,别人说的和做的很可能不一样。
80/20原则:你从20%的信息获得80%的价值,明白关键性的20%是什么
不要完美主义,完美主义的边际效用是 递减的
- 怎么做 :权衡结果,考虑结果,后续的结果,后续的后续的结果