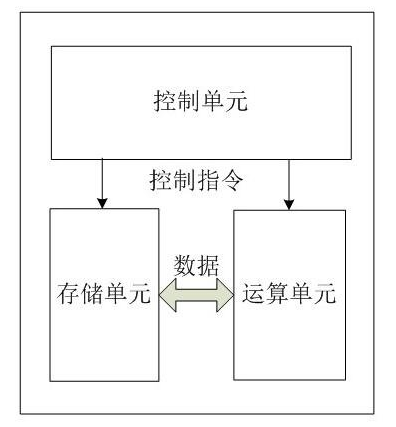
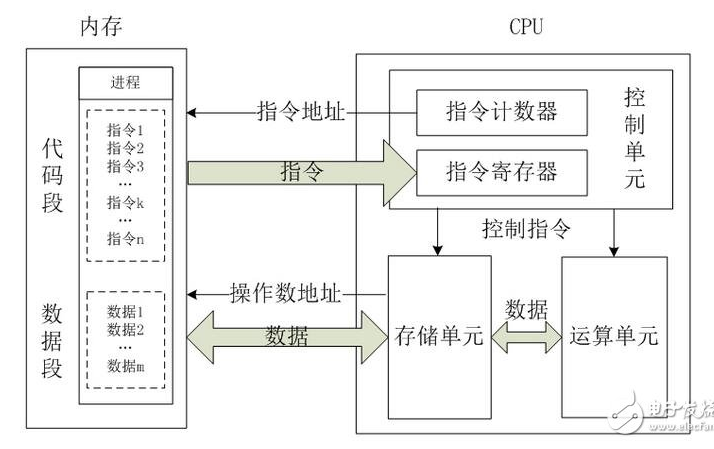
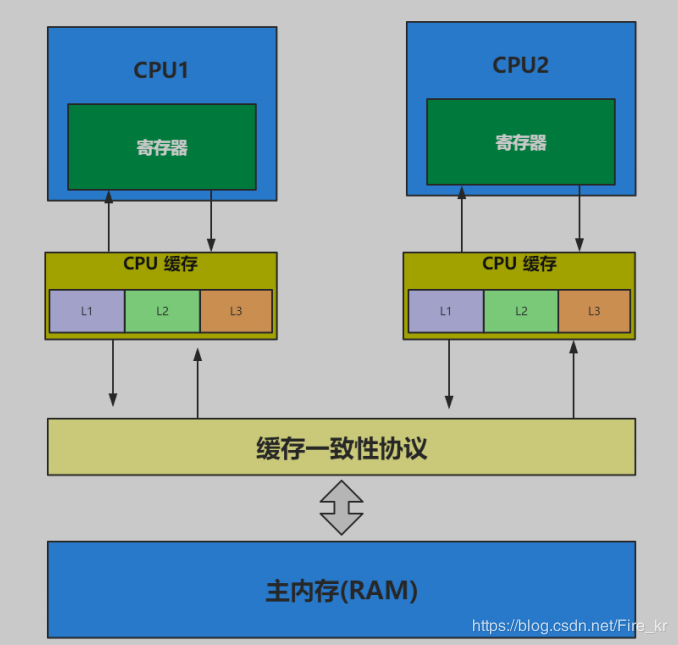
什么是MongoDB ?
MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统。
在高负载的情况下,添加更多的节点,可以保证服务器性能。
MongoDB 旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
NoSQL,指的是非关系型的数据库。NoSQL有时也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
NoSQL用于超大规模数据的存储。(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
主要特点
MongoDB 是一个面向文档存储的数据库,操作起来比较简单和容易。
你可以在MongoDB记录中设置任何属性的索引 (如:FirstName=”Sameer”,Address=”8 Gandhi Road”)来实现更快的排序。
你可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性。
如果负载的增加(需要更多的存储空间和更强的处理能力) ,它可以分布在计算机网络中的其他节点上这就是所谓的分片。
Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组。
MongoDb 使用update()命令可以实现替换完成的文档(数据)或者一些指定的数据字段 。
Mongodb中的Map/reduce主要是用来对数据进行批量处理和聚合操作。
Map和Reduce。Map函数调用emit(key,value)遍历集合中所有的记录,将key与value传给Reduce函数进行处理。
Map函数和Reduce函数是使用Javascript编写的,并可以通过db.runCommand或mapreduce命令来执行MapReduce操作。
GridFS是MongoDB中的一个内置功能,可以用于存放大量小文件。
MongoDB允许在服务端执行脚本,可以用Javascript编写某个函数,直接在服务端执行,也可以把函数的定义存储在服务端,下次直接调用即可。
MongoDB支持各种编程语言:RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
MongoDB安装简单。
安装
下载mongodb-linux-x86_64-3.6.3.tar.gz
解压tar -zxvf mongodb-linux-x86_64-3.0.6.tgz
在与bin同级的目录下建立data文件夹
mongo.config文件内容
1
2
3
4
5
6
7
8port=27017
logpath=/airthink/mongodb-linux-x86_64-3.6.3/mongod.log
pidfilepath=/airthink/mongodb-linux-x86_64-3.6.3/mongod.pid
logappend=true
fork=true
maxConns=3000
dbpath=/airthink/mongodb-linux-x86_64-3.6.3/data
auth=true启动./mongodb-linux-x86_64-3.6.3/bin/mongo
1
2
3
4
5
6
7var schema = db.system.version.findOne({_id:"authSchema"});//驱动版本5--SCRAM-SHA-1需要修改成:3--Mongodb-CR
schema. currentVersion = 3;
db.system.version.save(schema);
db.createUser({user:"admin",pwd:"mypass",roles:["readWriteAnyDatabase", "userAdminAnyDatabase", "dbAdminAnyDatabase"]});
windows下的启动命令到bin目录下 start mongodMongoDB用户角色配置
基本知识介绍
MongoDB基本的角色
- 数据库用户角色:read、readWrite;
- 数据库管理角色:dbAdmin、dbOwner、userAdmin;
- 集群管理角色:clusterAdmin、clusterManager、clusterMonitor、hostManager;
- 备份恢复角色:backup、restore;
- 所有数据库角色:readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase
- 超级用户角色:root (这里还有几个角色间接或直接提供了系统超级用户的访问(dbOwner 、userAdmin、userAdminAnyDatabase,其中MongoDB默认是没有开启用户认证的,也就是说游客也拥有超级管理员的权限。userAdminAnyDatabase:有分配角色和用户的权限,但没有查写的权限)
连接到MongoDB服务器
1 | 建库操作开始 |
Java程序连接MongoDB
1 | MongoCredential credential = MongoCredential.createCredential("username", "dbName", "password".toCharArray()); |
命令介绍
1 | 修改用户密码 |
mongoTemplate使用示例
对匹配到的数据进行更新(inc)
1 | Query query = new Query(); |
查询一条记录和保存(findOne/save)
1 | Account account = mongoTemplate.findOne(Query.query(Criteria.where("accountName").is(accountName)),Account.class); |
多条件匹配(并的关系)
1 | Criteria criteria = new Criteria(); |
多条件匹配(或的关系)
1 | Criteria criteria = new Criteria(); |
根据id查找并删除
1 | Account account = mongoTemplate.findById(id, Account.class); |
计数
1 | long count = mongoTemplate.count(Query.query(Criteria.where("accountName").is(accountName)), Account.class); |
模糊匹配并排序
1 | Criteria criteria = new Criteria(); |
distinct查询
1 | DBObject dbObject = new BasicDBObject("schoolId", bschool.get_id()); |
查找并所有排序
1 | mongoTemplate.find(new Query().with(new Sort(Direction.ASC, "order","createTime")), Bschool.class); |
in查询
1 | List<MpropValue> mpropValueList = mongoTemplate.find(Query.query(Criteria.where("propId").in(mprop1.get_id())), MpropValue.class); |
设置唯一字段
1 | //used 是1 将其他所有是1的更新为0 |
插入多条数据
1 | public ReturnStatus upsert(List<BspecialLink> specialLinks) { |
获取数据库所有集合名称
1 | Set<String> sets = mongoTemplage.getDb().getCollectionNames(); |
查询当天数据
private static Date getStartTime() {
Calendar todayStart = Calendar.getInstance();
todayStart.set(Calendar.HOUR_OF_DAY, 0);
todayStart.set(Calendar.MINUTE, 0);
todayStart.set(Calendar.SECOND, 0);
todayStart.set(Calendar.MILLISECOND, 0);
return todayStart.getTime();
}
private static Date getEndTime() {
Calendar todayEnd = Calendar.getInstance();
todayEnd.set(Calendar.HOUR_OF_DAY, 23);
todayEnd.set(Calendar.MINUTE, 59);
todayEnd.set(Calendar.SECOND, 59);
todayEnd.set(Calendar.MILLISECOND, 999);
return todayEnd.getTime();
}
Criteria criteria = new Criteria();
criteria.andOperator(
Criteria.where("type").is(type),
Criteria.where("typeId").is(typeId),
Criteria.where("userId").is(user.get_id()),
Criteria.where("createTime").gte(getStartTime())
.lte(getEndTime()));
return mongoTemplate.exists(Query.query(criteria), Zan.class);
其他
删除字段
1
db.yourcollection.update({},{$unset:{"需要删除的字段":""}},false,true)
将匹配到的值全部更新
1
db.getCollection("bschool").update({"state":0},{$set:{"state":"1"}},{'multi':true})
db.getCollection(“pdfChapterItem”).update({}, {$rename : {“remark” : “abbr”}}, false, true)//更新所有字段名
建立索引
1
db.bschoolScorelineDetail.ensureIndex({"schoolId":1,"type":1,"batch":1,"province":1},{"name":"schoolScorelineDetail"})
mongo中建立索引用ensureIndex({“字段1”:1,”字段2”:”-1”},{“name”:”索引名”}) 1和-1代表正序和倒序
mongo数据库备份操作(在mongo的安装目录的bin下执行如下命令)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15不带验证的数据库备份:
mongodump -d mrmf -o /tools/test mrmf数据库名 /tools/test要备份到的地方
不带验证的数据库恢复
mongorestore --db mrmf /tools/test/mrmf mrmf数据库名 /tools/test要恢复的数据
带验证的数据库备份:
mongodump -d mrmf -u admin -p "ie8*kskIkd123" --authenticationDatabase=admin -o /tools/test
带验证的数据库恢复:
mongorestore --db mrmf -u admin -p "ie8*kskIkd123" --authenticationDatabase=admin /tools/test/red开启慢日志
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37在客户端调用db.setProfilingLevel(级别) 命令来实时配置。可以通过db.getProfilingLevel()命令来获取当前的Profile级别。
> db.setProfilingLevel(2);
> {"was" : 0 , "ok" : 1}
> db.getProfilingLevel()
上面斜体的级别可以取0,1,2 三个值,他们表示的意义如下:
0 – 不开启
1 – 记录慢命令 (默认为>100ms)
2 – 记录所有命令
Profile 记录在级别1时会记录慢命令,那么这个慢的定义是什么?上面我们说到其默认为100ms,当然有默认就有设置,其设置方法和级别一样有两种,一种是通过添加–slowms启动参数配置。第二种是调用db.setProfilingLevel时加上第二个参数:
db.setProfilingLevel( level , slowms )
db.setProfilingLevel( 1 , 10 );
Mongo Profile 记录是直接存在系统db里的,记录位置 system.profile ,所以,我们只要查询这个Collection的记录就可以获取到我们的 Profile 记录了。
Profile 信息内容详解:
ts-该命令在何时执行.
millis Time-该命令执行耗时,以毫秒记.
info-本命令的详细信息.
query-表明这是一个query查询操作.
ntoreturn-本次查询客户端要求返回的记录数.比如, findOne()命令执行时 ntoreturn 为 1.有limit(n) 条件时ntoreturn为n.
query-具体的查询条件(如x>3).
nscanned-本次查询扫描的记录数.
reslen-返回结果集的大小.
nreturned-本次查询实际返回的结果集.
update-表明这是一个update更新操作.
upsert-表明update的upsert参数为true.此参数的功能是如果update的记录不存在,则用update的条件insert一条记录.
moved-表明本次update是否移动了硬盘上的数据,如果新记录比原记录短,通常不会移动当前记录,如果新记录比原记录长,那么可能会移动记录到其它位置,这时候会导致相关索引的更新.磁盘操作更多,加上索引更新,会使得这样的操作比较慢.
insert-这是一个insert插入操作.
getmore-这是一个getmore 操作,getmore通常发生在结果集比较大的查询时,第一个query返回了部分结果,后续的结果是通过getmore来获取的。
1 | #下面是一个超过200ms的查询语句 |
MongoDB 查询优化
- 如果发现 millis 值比较大,那么就需要作优化。
- 如果docsExamined数很大,或者接近记录总数(文档数),那么可能没有用到索引查询,而是全表扫描。
- 如果keysExamined数为0,也可能是没用索引。
- 结合 planSummary 中的显示,上例中是 “COLLSCAN, COLLSCAN” 确认是全表扫描
- 如果 keysExamined 值高于 nreturned 的值,说明数据库为了找到目标文档扫描了很多文档。这时可以考虑创建索引来提高效率。
- 索引的键值选择可以根据 query 中的输出参考,上例中 filter:包含了 jzrq和jglxfldm 并且按照RsId排序,所以 我们的索引索引可以这么建: db.f10_2_8_3_jgcc.ensureindex({jzrq:1,jglxfldm:1,RsId:1})
聚合操作
1 | 示例一 |

1 | 示例二 |
AggregationResults ar = mongoTemplate.aggregate(aggregation,
Ugclock.class, BasicDBObject.class);
1 | for (BasicDBObject basicDBObject : ar) { |
翻页
项目当中模拟插入了120W条数据,在同一个文档当中单纯查询数据的速度还不错,主要是对查询的文档字段添加了索引,但是对查询结果的前台分页确有问题。具体来说是不设置任何查询条件的时候,会查询出来将近120W条满足条件的结果,使用mongodb的limit()和skip() 来取出来 第一页前20条数据,这样在后台的java程序当中只是这20条数据占用内存。
代码具体形式类似于用mongodb客户端执行db.feedbackInfo.find(criteria).skip(0).limit(20) 获得第一页0-20条数据db.feedbackInfo.find(criteria).skip(20).limit(20) 获得第二页20-40条数据……db.feedbackInfo.find(criteria).skip(N).limit(20) 获得第二页N-N+20条数据但问题在于随着不断翻页,skip的值N会越来越大,前台的反应越来越慢。很直接的一个表现就是在前台从第一页直接跳转进入最后一页根本反应不过来。对于这个实际问题,原因就是本书这里所言的skip略过大量结果会带来性能问题,再根源地说是mongodb还不够完善,索引本身还比较简单。具体的这个分页效率的问题,有两种思路:第一,等mongodb升级,优化这个skip的执行效率。第二,不用skip()而实现分页效果。这个思路的基础就是mongodb本身对于where查询和limit()的效率还比较不错,也就是本来分页的那个查询用where和limit速度还可以的前提(一般就是需要建立必要的索引)。假如这个前提不成立,那没法讨论。本书接下来具体讨论了不使用skip对结果分页的实现例子,这个本质是对信息系统增加一个查询中间量——上次查询的业务数值,在逻辑上承担起跟skip相对等价的功能。比如说是第一页查询是按照一个日期date值查询,第一次用db.foo.find().sort({“date”,-1}).limit(20)而点击下一页的时候,事先将上次查询的date的边界值给传递过去,第二页查询的时候就使用新的find条件查询db.foo.find({“date”:{“$gt”:latest.date}}); 而后再对查询结果排序即可这种绕过skip的方式评价:第一,很难比较方便地解决所有的分页问题,简单来说 对于使用正则表达式的查询,根本无法通过记录边界条件来实现。第二,不得不多传递上次查询的那个边界条件,增加了工作量,不够优雅。第三,只能够解决一页一页往下翻页的问题,如果我要从第1页直接跳到100页,就束手无策
翻页的实现一
skip实现跳页(比较简单,数据量大了不行)
/**
*db.getCollection('user').find({})是指查询全部。
*sort()设置排序,本示例是指以_id作为条件,正序排序。若将数字1改为-1,则为倒序。
*skip()设置跳页,本示例是指跳过前10条,从第11条开始显示。
*limit()设置每页的显示数量,本例是指每页限制显示10条。
*/
db.getCollection('user').find({}).sort({"ID":1}).skip(10).limit(10)
非skip实现跳页
原理:以自增_id作为主条件,获取前一页的最后一条记录,查询之后的指定条记录
//根据_id,查询前10条
var a = db. getCollection('user').find({}).sort("_id",1).limit(10)
//定义变量last
var last = null
//循环遍历
while(a.hasNext()){
last=a.next;//循环到最后,last接收的是最后一条的信息
}
//核心是"_id":{"$gt":last._id},即查询大于最后一条的_id的后10条信息
db.getCollection('slt').find({"_id":{"$gt":last._id}}).sort({_id:1}).limit(10)
翻页的实现二(非skip实现跳页,以自增_id作为主条件)
private List<JSONObject> findOrderList(Map<String,Object> paramOptions,int page,int size,String sidx,String sord) throws Exception {
//连接数据库
MongoCollection<Document> mongoCollection = getMdbCollection();
//进行第一次查询,条件中没有skip
MongoCursor<Document> iterable = mongoCollection.find().limit(size).sort(new BasicDBObject("_id", 1)).iterator();
//定义orderItems,用以接收查询的信息
List<JSONObject> orderItems = new ArrayList<JSONObject>();
//如果只有一页或第一页,则走此条件,否,则走else
if(page == 1){
//遍历
while (iterable.hasNext()) {
Document next = iterable.next();
JSONObject a =JSONObject.parseObject(next.toJson());
orderItems.add(a);
}
}else{
MongoCursor<Document> iterable2 = mongoCollection.find().limit(size*(page-1)).sort(new BasicDBObject("_id", 1)).iterator();
//定义变量last,用以存储每页的最后一条记录
Document last = null;
while (iterable2.hasNext()) {
last = iterable2.next();
}
//定义condition,用以添加【$gt:每页最后一条记录的_id值】,作为查询条件
Map<String, Object> condition = new HashMap<>();
if (null != last.get("_id")) {
condition.put("$gt",last.get("_id"));
}
MongoCursor<Document> iterable3 = mongoCollection.find(condition).limit(size).sort(new BasicDBObject("_id", 1)).iterator();
//遍历
while (iterable.hasNext()) {
Document next = iterable.next();
JSONObject a =JSONObject.parseObject(next.toJson());
orderItems.add(a);
}
return orderItems;
}
注:上面是按_id正序排列的,如果想要按照倒序排列,则需要将condition.put("$gt",last.get("_id"))改为condition.put("$lt",last.get("_id")),将sort(new BasicDBObject("_id", 1)改为sort(new BasicDBObject("_id", -1)。
mongo高级
本地搭建副本集
mongo的版本
version 3.6.5
副本集文件夹准备
mongodb3.6 同目录下建立文件夹,存放数据
data/mongo/27017,data/mongo/27018,data/mongo/27019
同目录下建立文件夹存放日志数据
data/mongo/27017log,data/mongo/27018log,data/mongo/27019log
启动
mongod --port 27017 --dbpath /data/mongo/27017 --logpath /data/mongo/27017log/27017.log --replSet rs-local-test --logappend
mongod --port 27018 --dbpath /data/mongo/27018 --logpath /data/mongo/27018log/27018.log --replSet rs-local-test --logappend
mongod --port 27019 --dbpath /data/mongo/27019 --logpath /data/mongo/27019log/27019.log --replSet rs-local-test --logappend
三个服务器启动完毕之后,不要关闭。另开一个cmd窗口,连接到27017端口的服务器(连接其他端口也可以),每次启动,主服务器可能会不一样,如果连接的是主服务器,前缀会变成如下PRIMARY,如果是从服务器,前缀会变成SECONDARY
创建配置文件
创建一个配置文件,在配置文件中列出每一个成员,知道彼此的存在(第二次启动就不需要再配置)
use test
witched to db test
rs.initiate({
"_id":"rs-local-test01",
"members":[
{"_id":0,"host":"127.0.0.1:27017"},
{"_id":1,"host":"127.0.0.1:27018"},
{"_id":2,"host":"127.0.0.1:27019"}
]
})
{
"ok" : 1,
"operationTime" : Timestamp(1596076771, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1596076771, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="
"keyId" : NumberLong(0)
}
}
}
查看状态信息
rs-local-test:OTHER> rs.status()
{
"set" : "rs-local-test",
"date" : ISODate("2020-07-30T02:40:29.243Z"),
"myState" : 1,
"term" : NumberLong(1),
"heartbeatIntervalMillis" : NumberLong(2000),
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(1596076823, 1),
"t" : NumberLong(1)
},
"readConcernMajorityOpTime" : {
"ts" : Timestamp(1596076823, 1),
"t" : NumberLong(1)
},
"appliedOpTime" : {
"ts" : Timestamp(1596076823, 1),
"t" : NumberLong(1)
},
"durableOpTime" : {
"ts" : Timestamp(1596076823, 1),
"t" : NumberLong(1)
}
},
"members" : [
{
"_id" : 0,
"name" : "127.0.0.1:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 286,
"optime" : {
"ts" : Timestamp(1596076823, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2020-07-30T02:40:23Z"),
"infoMessage" : "could not find member to sync fr
"electionTime" : Timestamp(1596076782, 1),
"electionDate" : ISODate("2020-07-30T02:39:42Z"),
"configVersion" : 1,
"self" : true
},
{
"_id" : 1,
"name" : "127.0.0.1:27018",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 57,
"optime" : {
"ts" : Timestamp(1596076823, 1),
"t" : NumberLong(1)
},
"optimeDurable" : {
"ts" : Timestamp(1596076823, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2020-07-30T02:40:23Z"),
"optimeDurableDate" : ISODate("2020-07-30T02:40:2
"lastHeartbeat" : ISODate("2020-07-30T02:40:28.47
"lastHeartbeatRecv" : ISODate("2020-07-30T02:40:2
),
"pingMs" : NumberLong(0),
"syncingTo" : "127.0.0.1:27017",
"configVersion" : 1
},
{
"_id" : 2,
"name" : "127.0.0.1:27019",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 57,
"optime" : {
"ts" : Timestamp(1596076823, 1),
"t" : NumberLong(1)
},
"optimeDurable" : {
"ts" : Timestamp(1596076823, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2020-07-30T02:40:23Z"),
"optimeDurableDate" : ISODate("2020-07-30T02:40:2
"lastHeartbeat" : ISODate("2020-07-30T02:40:28.47
"lastHeartbeatRecv" : ISODate("2020-07-30T02:40:2
),
"pingMs" : NumberLong(0),
"syncingTo" : "127.0.0.1:27018",
"configVersion" : 1
}
],
"ok" : 1,
"operationTime" : Timestamp(1596076823, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1596076823, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="
"keyId" : NumberLong(0)
}
}
}
如果是第二次启动,可以直接查看状态信息,不需要在设置配置文件。
查看状态信息,可以看到主服务器和备份服务器:
rs-local-test:SECONDARY>use test
switched to db test
rs-local-test:SECONDARY> db.isMaster()
{
"hosts" : [
"127.0.0.1:27017",
"127.0.0.1:27018",
"127.0.0.1:27019"
],
"setName" : "rs-local-test",
"setVersion" : 1,
"ismaster" : false,
"secondary" : true,
"primary" : "127.0.0.1:27019",
"me" : "127.0.0.1:27017",
"lastWrite" : {
"opTime" : {
"ts" : Timestamp(1596079583, 1),
"t" : NumberLong(5)
},
"lastWriteDate" : ISODate("2020-07-30T03:26:23Z"),
"majorityOpTime" : {
"ts" : Timestamp(1596079583, 1),
"t" : NumberLong(5)
},
"majorityWriteDate" : ISODate("2020-07-30T03:26:23Z")
},
"maxBsonObjectSize" : 16777216,
"maxMessageSizeBytes" : 48000000,
"maxWriteBatchSize" : 100000,
"localTime" : ISODate("2020-07-30T03:26:25.289Z"),
"logicalSessionTimeoutMinutes" : 30,
"minWireVersion" : 0,
"maxWireVersion" : 6,
"readOnly" : false,
"ok" : 1,
"operationTime" : Timestamp(1596079583, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1596079583, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
读写测试
连接主服务器后,可以写入数据:
重新启动一个cmd,连接一个备份服务器,查看是否数据被复制:
备份节点可能会落后于主节点,可能没有最新写入数据,所以备份节点默认情况下会拒绝读取请求,这是为了保护应用程序,以免意外连接到备份节点,读取到过期数据:
rs-local-test:SECONDARY> db.foo.find()
Error: error: {
"operationTime" : Timestamp(1596079503, 1),
"ok" : 0,
"errmsg" : "not master and slaveOk=false",
"code" : 13435,
"codeName" : "NotMasterNoSlaveOk",
"$clusterTime" : {
"clusterTime" : Timestamp(1596079503, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
从备份节点读取数据,需要设置标识:
db.getMongo().setSlaveOk();
节点变更
在主节点插入数据后,如果有备份节点服务器没有启动,当在该备份启动后,也可以查询到写入的数据:
不能对备份节点执行写入操作,备份节点只能通过复制功能写入数据,不接受客户端的写入请求:
rs-local-test:SECONDARY>
可以随时添加或删除成员,先按之前的方法创建一个备用服务器,再添加进去:
rs.add(‘127.0.0.1’:4444)
rs是一个全局变量,其中包含与复制相关的辅助函数。
删除成员:
rs.remove(‘127.0.0.1’:4444)
添加或删除完可通过 db.isMaster()查看修改结果
也可rs.config();
rs-local-test:SECONDARY> rs.config()
{
"_id" : "rs-local-test",
"version" : 1,
"protocolVersion" : NumberLong(1),
"members" : [
{
"_id" : 0,
"host" : "127.0.0.1:27017",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
},
{
"_id" : 1,
"host" : "127.0.0.1:27018",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
},
{
"_id" : 2,
"host" : "127.0.0.1:27019",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
}
],
"settings" : {
"chainingAllowed" : true,
"heartbeatIntervalMillis" : 2000,
"heartbeatTimeoutSecs" : 10,
"electionTimeoutMillis" : 10000,
"catchUpTimeoutMillis" : -1,
"catchUpTakeoverDelayMillis" : 30000,
"getLastErrorModes" : {
},
"getLastErrorDefaults" : {
"w" : 1,
"wtimeout" : 0
},
"replicaSetId" : ObjectId("5f2232e3b3ef9f7db4cb682d")
}
}
以上参考自 https://www.cnblogs.com/a-horse-mosaic/p/9284297.html
问题汇总
如何开启读写分离
默认情况下驱动是从Replica Set 集群中的 Primary 上进行读写的,应用可以在读多写少的场景下开启读写分离,提高效率。
读取偏好(Read Preference)参数
primary 主节点,默认模式,读操作只在主节点,如果主节点不可用,报错或者抛异常。
primaryPreferred 首选主节点,如果主节点不可用,如故障转移,读操作在从节点。
secondary 从节点,读操作只在从节点,如果从节点不可用,报错或者抛异常。
secondaryPreferred 首选从节点,大多情况下读操作在从节点,特殊情况(如单主节点架构)读操作在主节点。
nearest 最邻近节点,读操作在最邻近的成员,可能是主节点或者从节点
在Mongodb中最多能创建多少集合?
默认情况下,MongoDB 的每个数据库的命名空间保存在一个 16MB 的 .ns 文件中,平均每个命名占用约 628 字节,也即整个数据库的命名空间的上限约为 24000。
每一个集合、索引都将占用一个命名空间。所以,如果每个集合有一个索引(比如默认的 _id 索引),那么最多可以创建 12000 个集合。如果索引数更多,则可创建的集合数就更少了。同时,如果集合数太多,一些操作也会变慢。甚至使得MongoDB集群无法服务的情况发生!
MongoDB有传统数据库的事务和事务回滚么?
没有,请不要把它当成关系型数据库来使用,对于MongoDB集群来说,默认情况下数据也不是强一致性的,而是最终一致性。如果对数据一致性比较敏感建议更改WriteConcern级别,但后果是降低了性能,请酌情考虑。
MongoDB有命名规范么?
- 不能是空字符串
- 不能含有.、’’、*、/、\、<、>、:、?、$、\0。建议只使用ASCII码中字母和数字
- 数据库名区分大小写
- 数据库名长度最多为64字节
- 集合名不能包含\0字符,这个字符表示集合名的结束
- 集合名不能是空字符串””
- 集合名不能使用系统集合的保留前缀”system.”
- 集名名中不建议包含字符’$’,虽然很多驱动程序可以支持包含此字符的集合名
MongoDB有系统保留库名么?
- admin
- local
- config
MongoDB有连接池么?
MongoDB驱动中其实已经是一个现成的连接池了,而且线程安全。这个内置的连接池默认初始了100个连接,每一个操作(增删改查等)都会获取一个连接,执行操作后释放连接。
【题外话】请务必记得关闭资源,并且设置合理的池子连接数和超时时间。
内置连接池有多个重要参数,分别是
- connectionsPerHost:每个主机答应的连接数(每个主机的连接池大小),当连接池被用光时,会被阻塞住,默认值为100
- threadsAllowedToBlockForConnectionMultiplier:线程队列数,它和上面connectionsPerHost值相乘的结果就是线程队列最大值。如果连接线程排满了队列就会抛出“Out of semaphores to get db”错误,默认值为5,则最多有500个线程可以等待获取连接
- maxWaitTime: 被阻塞线程从连接池获取连接的最长等待时间(ms)。默认值为120,000
- connectTimeout:在建立(打开)套接字连接时的超时时间(ms)。默认值为10,000
- socketTimeout:套接字超时时间(ms)。默认值为0,无限制(infinite)
- autoConnectRetry:这个控制是否在连接时,会自动重试,2.13驱动已经【废弃】,请使用connectTimeout代替它
连接池的MaximumPoolSize要有个合理值,否则这个值数据量的连接都被占用,后面再有新的连接创建时就要等待了,而不能超出池上限新建连接。除此之外还要设置合理的连接等待,连接超时时间,以防止一个连接占用时间过长,影响其它连接请求。
connectTimeout 和 socketTimeout 的区别
一次完整的请求包括三个阶段:
- 建立连接
- 数据传输
- 断开连接
如果与服务器(这里指数据库)请求建立连接的时间超过ConnectTimeout,就会抛 ConnectionTimeOutException,即服务器连接超时,没有在规定的时间内建立连接。
如果与服务器连接成功,就开始数据传输了。
如果服务器处理数据用时过长,超过了SocketTimeOut,就会抛出SocketTimeOutExceptin,即服务器响应超时,服务器没有在规定的时间内返回给客户端数据。
所以这该死的超时该怎么配?
这里有一份国外写的关于超时的建议:
http://blog.mongolab.com/2013/10/do-you-want-a-timeout/
上文给出的通常情况下:connectTimeout=5000,socketTimeout=0
关于WriteConcern
MongoDB提供了一个配置参数:write concern 来让用户自己衡量性能和写安全。分布式数据库中这样的参数比较常见,记得Cassandra中也有一个类似参数,不过那个好像是要写入几个节点返回成功。其实道理都一样分布式的集群环境考虑到性能因素不能确保每个成员都写入后在返回成功,所以只能交给用户根据实际场景衡量。
- Unacknowledged
- 这个级别也属于比较低的级别,以前这个级别是驱动配置的默认级别,不过后来调整成Acknowledged级别。在这个级别下,这个驱动会根据当前系统的网络配置进行网络问题的检测,不等待Mongd的返回。代码测试:本地网络问题是否有异常?本地网络无问题是远程server问题是否异常?
- Acknowledged
- 这个级别算是中等级别的配置,这个级别能够拿到mongod的返回信息:dupkey Error,以及一些其他的问题。现在这个级别是驱动的默认级别,估计是10gen公司发现好多人评价Mongodb不靠谱后改的。一般系统这个级别也就够用了。由于默认级别是Acknowledged,内部用getLastError方法检查是否写入成功的时候是也不用设置任何参数,对与Replset来说可以在配置中进行getLastErrorDefaults的配置,如果没有的话默认则是Master收到就ok。
- Journaled
- 等到操作记录到Journal Log中才返回操作结果,也就是下一次JournaledLog提交。这种情况可以容忍服务器突然宕机,断电等意外的恢复。出去上边的配置还要在启动mongod的时候加上journaling 参数确保可以使用。commitlog提交间隔时间是可以配置的,单磁盘设备(physical volume, RAID device, or LVM volume)每100ms提交一次,和数据文件刷出相同频率,日志和数据分开磁盘设备的30ms提交一次。在插入数据是如果使用{j:true}则会缩短到已配置的默认设置1/3的时间。
- Replica Acknowledged
- 在副本集中如果w设置为2的话则至少已经吸入到一个secondary中,我猜测写入secondary这个级别是Acknowledged级别,majority是多个secondary已经写入。如果手贱设置w参数大于replset中需要复制的secondarys的话,操作就一直等待直到达到已写入数据的服务器数量符合要求,也可以设置timeout值来指明最长等待时间。{ getLastError: 1, w: 2, wtimeout:5000 }
MongoDB的锁机制
MongoDB的锁机制和一般关系数据库如 MySQL(InnoDB), Oracle 有很大的差异,InnoDB 和 Oracle 能提供行级粒度锁,而 MongoDB v2 只能提供库级粒度锁,这意味着当 MongoDB 一个写锁处于占用状态时,其它的读写操作都得干等。
初看起来库级锁在大并发环境下有严重的问题,但是 MongoDB 依然能够保持大并发量和高性能,这是因为 MongoDB 的锁粒度虽然很粗放,但是在锁处理机制和关系数据库锁有很大差异,主要表现在
- MongoDB 没有完整事务支持,操作原子性只到单个 document 级别,所以通常操作粒度比较小;
- MongoDB 锁实际占用时间是内存数据计算和变更时间,通常很快;
- MongoDB 锁有一种临时放弃机制,当出现需要等待慢速 IO 读写数据时,可以先临时放弃,等 IO 完成之后再重新获取锁。
通常不出问题不等于没有问题,如果数据操作不当,依然会导致长时间占用写锁,比如下面提到的前台建索引操作,当出现这种情况的时候,整个数据库就处于完全阻塞状态,无法进行任何读写操作,情况十分严重。
解决问题的方法,尽量避免长时间占用写锁操作,如果有一些集合操作实在难以避免,可以考虑把这个集合放到一个单独的 MongoDB 库里,因为 MongoDB 不同库锁是相互隔离的,分离集合可以避免某一个集合操作引发全局阻塞问题。
建索引导致数据库阻塞
上面提到了 MongoDB 库级锁的问题,建索引就是一个容易引起长时间写锁的问题,MongoDB 在前台建索引时需要占用一个写锁(而且不会临时放弃),如果集合的数据量很大,建索引通常要花比较长时间,特别容易引起问题。
解决的方法很简单,MongoDB 提供了两种建索引的访问,一种是 background 方式,不需要长时间占用写锁,另一种是非 background 方式,需要长时间占用锁。使用 background 方式就可以解决问题。
例如,为超大表 posts 建立索引
//千万不用使用
db.posts.ensureIndex({user_id: 1})
//而应该使用
db.posts.ensureIndex({user_id: 1}, {background: 1})